

Transformers have played a crucial role in natural language processing tasks in the last decade. Their success attributes mainly to their ability to extract and exploit temporal information.
When a certain method works well in a domain, it is normal to expect to see studies that try to bring that method to other domains. This was the case with transformers as well, and the domain was computer vision. Introducing transformers to vision tasks was a huge success, bringing numerous similar studies afterward.
The vision transformer (ViT) was proposed in 2020, outperforming its convolutional neural network (CNN) counterpart in the image classification tasks. Its main benefits were at a large scale since they require more data or stronger regularisation.
ViT inspired many researchers to dive deeper into the rabbit hole of transformers to see how further they can go in different tasks. Most of them focused on image-related tasks, and they obtained really promising results. However, the application of ViTs into the video domain remained an open problem, more or less.
When you think of it, transformers, more importantly, attention-based architectures, look like the perfect structure to be used with videos. They are the intuitive choice for modeling the dependency in natural languages and extracting contextual relationships between the words. A video also contains these properties, so why not use the transformer to process videos? This is the question the authors of ViViT asked, and they came up with an answer.
Most state-of-the-art video-related solutions use 3D-convolutional networks, but their complexity makes it challenging to achieve proper performance on commodity devices. Some studies focused on adding the self-attention property of transformers into the 3D-CNNs to better capture long-term dependencies within the video.
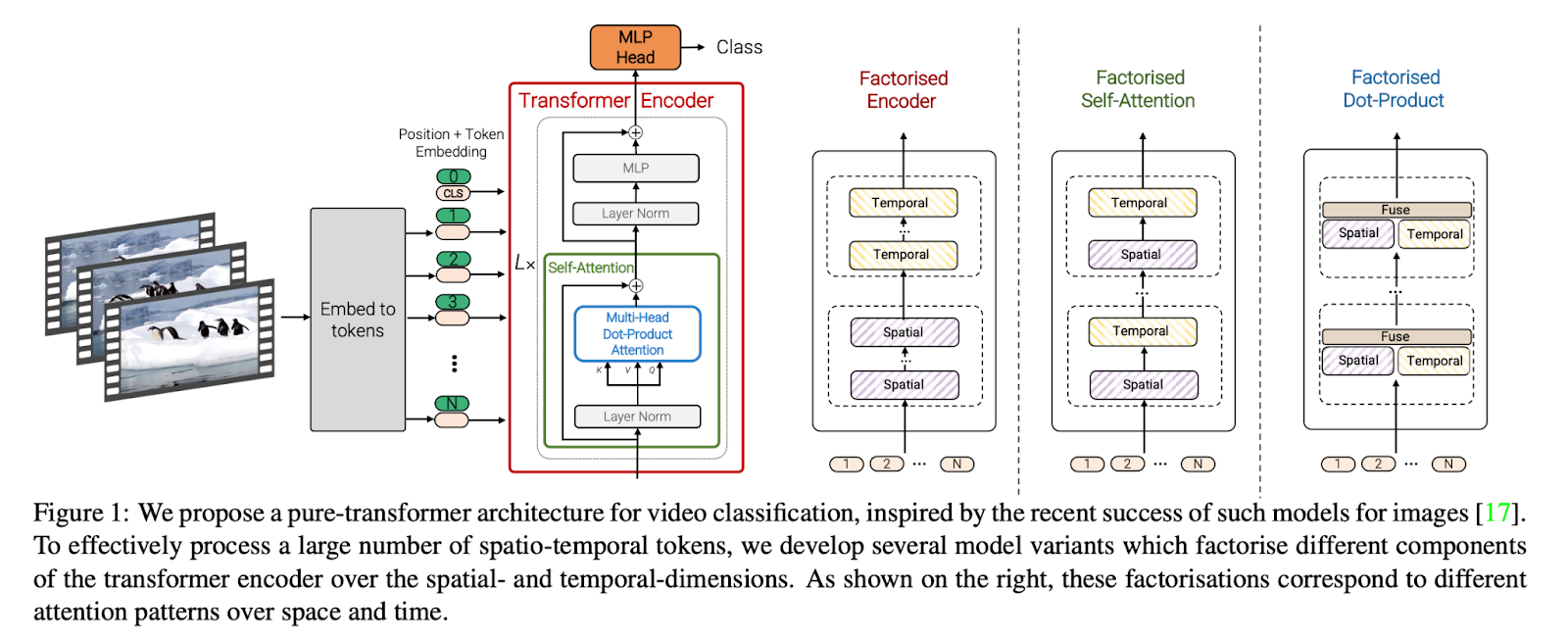
ViViT explores the use of pure transformers for classifying videos. Spatial and temporal tokens are extracted from the input video to be used in the self-attention module, which is the primary function of a transformer. Token extraction plays a crucial part here. Therefore, ViViT proposes several different approaches to do so. Also, ViViT proposes an approach to regularize the model during training which can be done by using pre-trained image models. Doing so enables ViViT to train efficiently using fewer datasets, as constructing a large-scale video dataset is a really costly process.
Moreover, since convolution neural networks have been the flag carriers in computer vision tasks for the last decade, the community has proposed multiple valuable tricks that have made them successful. These tricks are too valuable to be simply ignored, and ViViT authors wanted to examine their effects on transformers. However, it is not as simple as copy-pasting those solutions to transformers, as they have different characteristics. That’s why they conducted an in-depth analysis of tokenization strategies, model architecture, and regularisation methods to develop the most appropriate design choices.

ViViT proposes different embedding and transformer approaches for video tokenization. Tubelet and uniform-frame embedding approaches are examined. For attention, four different approaches are studied, each with its own advantages and disadvantages for certain use cases. It’s a trade-off between efficiency and accuracy, so one can choose the sweet spot required for their practice.