

Google announced their new text-to-image diffusion model, DreamBooth. This AI-tool can generate a myriad of images of a user’s desired subject in different contexts using the guidance of a text prompt.
“Can you imagine your own dog traveling around the world, or your favorite bag displayed in the most exclusive showroom in Paris? What about your parrot being the main character of an illustrated storybook?”, reads the introduction of the paper.
The key idea for the model is to allow users to create photorealistic renditions of their desired subject instance and bind it with the text-to-image diffusion model. Thus, this tool proves to be effective for synthesising subjects in different contexts.
Google’s DreamBooth takes a moderately different approach when compared to other recently released text-to-image tools like DALL-E2, Stable Diffusion, Imagen, and Midjourney by providing more control of the subject image and then guiding the diffusion model using text based inputs.
DreamBooth vs the world
While the existing model, DALL-E2, can synthesise and create semantic variations of a given single image, it fails to reconstruct the appearance of the subject and can also not modify the context. DreamBooth can understand the subject of the given image, separate it from the existing context in the image, and then synthesise it into a new desired context with high fidelity.

The task to seamlessly blend an object into a scene is a challenging task given the existing techniques are limited to text-to-image only models with DALL-E2 allowing uploading only one image for synthesis. DreamBooth’s AI with just three to five input images of the subject can output a myriad of images within different contexts with a text prompt.
3D reconstruction tools have a similar challenge of not being able to generate spaces with subjects in different lightings. Google Research’s RawNeRF solved this problem by generating 3D spaces from a set of single images.
Another observed problem for image synthesis is the loss of information during the diffusion process like finding the noise map and a vector that relates to a generated image. While Imagen or DALL-E2 attempt to optimally embed and represent the concept, limiting them to the style of the desired output image, DreamBooth fine-tunes the model to embed the subject within the output domain of the model by linking the input subject to a unique identifier. This results in generation of variable and novel images of the subject while keeping and preserving the identity of the subject.
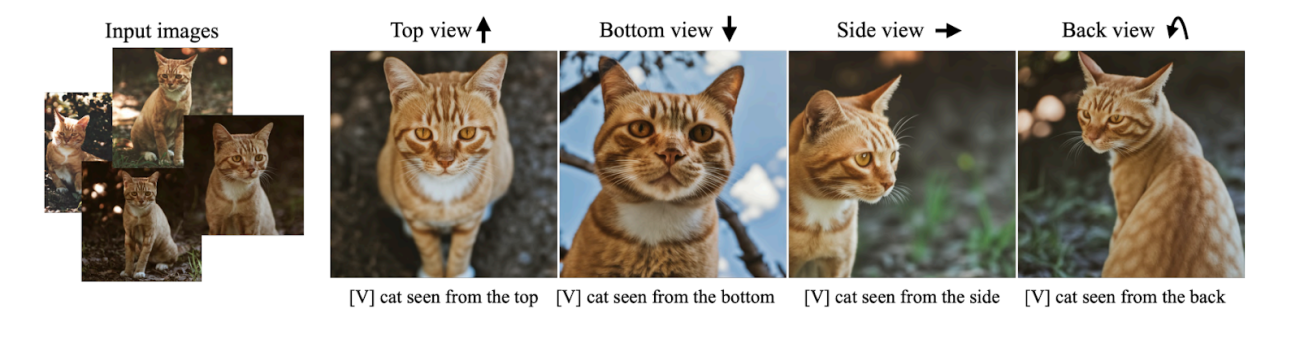
DreamBooth can also render the subject under different camera viewpoints with the help of only a few input images. Even if the input images do not include information about the subject from different angles, the AI can predict the properties of the subject and then synthesise it within the text-guided context.
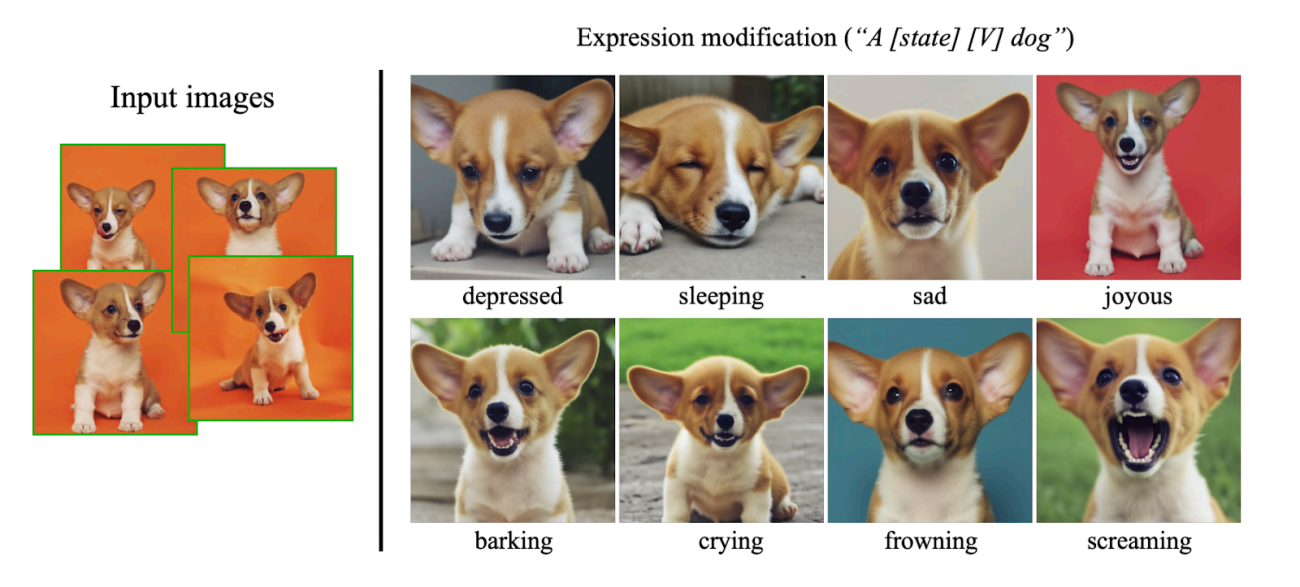
This model can also synthesise the images to output different emotions, accessories, or modifications to the colours, with help of text prompt allowing further creative freedom and customisation for the users.
Limitations
To generate high-detailed iterations in the subject, the command prompt becomes a limitation. DreamBooth can make variations in the context of the subject but to make changes within the subject, the model faces glitches within the frame.
Another issue is overfitting of the output image into the input image. The subject sometimes is not assessed or is blended with the context of the given images if the input images are less in number. This also occurs when prompting a context for generation that is rare.

Some other limitations are inability to synthesise images or rarer or more complex subjects and also the variability in the fidelity of the subject creating hallucinating variations and discontinuous features of the subject. The input context is often blended within the subject from the input images.
More power to users
Most text-to-image models render outputs using millions of parameters and libraries to generate an image based on the single text input. DreamBooth makes itself more easy and accessible for the users as it only requires an input of 3~5 captured images of the subject along with a textual context. The trained model then is able to reuse the materialistic qualities of the subject obtained from the images to recreate it within different settings and viewpoints while maintaining the subject’s distinctive features.
Most text-to-image models rely on specific keywords and could be biased towards specific attributes when rendering images. DreamBooth gives users the choice to imagine their desired subject within a new environment or context and generate photorealistic outputs.